介绍
- 了解FIFO和LIFO处理顺序的原理
- 实现这两个数据结构
- 熟悉内置的队列和栈结构
- 解决基本的队列相关问题,尤其是BFS
- 解决基本的栈相关问题
- 理解当你使用 DFS 和其他递归算法来解决问题时,系统栈是如何帮助你的。
队列:先入先出的数据结构
- 理解FIFO和队列的定义;
- 能够自己实现队列;
- 熟悉内置队列结构;
- 使用队列来解决简单的问题;
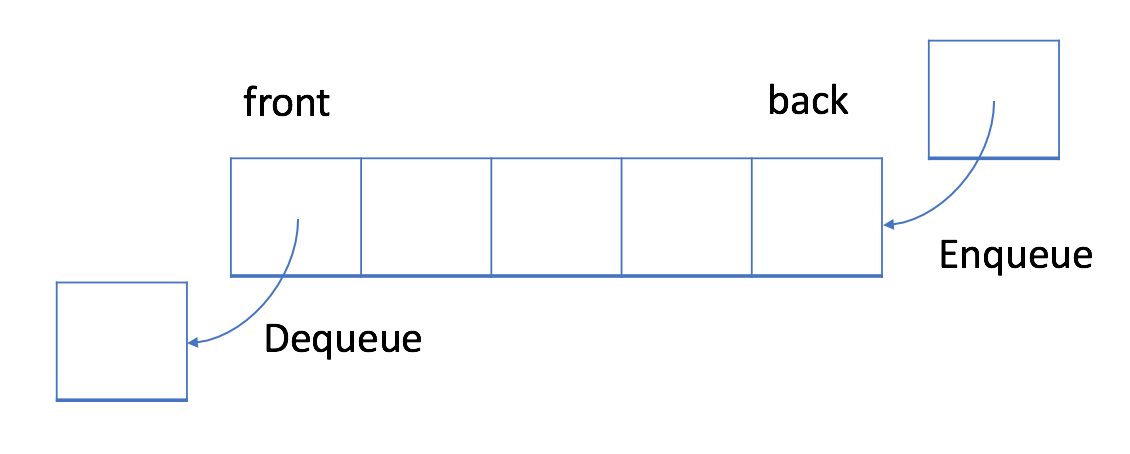
在FIFO数据结构中,将首先处理添加到队列中的第一个元素。
插入(insert)操作也称为入队(enqueue),新元素始终被添加在队列的末尾。删除(delete)操作也被称为出队(dequeue)。你只能移除第一个元素。
队列-实现
为了实现队列,我们可以使用动态数组和指向队列头部的索引。
如上所述,队列应支持两种操作:入队和出队。入队会向队列追加一个新元素,而出队会删除第一个元素。 所以我们需要一个索引来指出起点。
1 | class MYQueue { |
循环队列
此前,简单但是低效的队列实现。
更有效的方法是使用循环队列。使用固定大小的数组和两个指针来指示起始位置和结束位置。目的是重用之前被浪费的存储。
循环队列的实现:
- 初始化queue,设置queue的
maxSize,head和tail节点 - 入队
enqueue:检查元素个数是否是maxSize-1;- Yes,返回Queue满了
- No,在tail的位置上增加新元素,并增加
tail节点
- 出队
dequeu:检查队列中个数是否为0- Yes,返回Queue是空
- No,减少
head节点
- 找
size:- tail >= head,
size = (tail - head) + 1 - head > tail,
size = maxSize - (head - tail) + 1
- tail >= head,
1 | class MyCircularQueue { |
队列和BFS(breadth-first-search)
广度优先搜索(BFS)是一个常见应用是找出从根结点到目标结点的最短路径。
- 结点的处理顺序
第一轮中,处理根结点;第二轮中,处理根结点旁边的结点;在第三轮中,处理距根结点两步的结点;等等
与树的层序遍历类似,越是接近根结点的结点将越早地遍历。
如果在第k轮中将结点X添加到队列中,则根节点与X之间的最短路径的长度恰好是k。也就是说,第一次找到目标结点时,你已经处于最短路径中。 - 队列的入队和出队顺序是什么?
首先将根节点排入队列。在每一轮中,逐个处理已经在队列中的结点,并将所有邻居添加到队列中。新添加的结点不会立即遍历,而是在下一轮中处理。
结点的处理顺序与它们添加到队列的顺序是完全相同的顺序,即先进先出
广度优先搜索-模板
1 | /** |
- 每一轮中,队列中的节点是
等待处理的结点。 - 在每个更外一层的
while循环之后,我们距离根结点更远一步。遍历step指示从根结点到正在访问的当前结点的距离。
1 | int BFS(Node root, Node target) { |
200.岛屿的个数
算法:广度优先搜索
线性扫描整个二维网络,如果一个结点包含1,则以其为根节点启动广度优先搜索。将其放入队列中,(上下左右都得设置入队)并将值设为0以标记访问过该结点。迭代地搜索队列中每个结点,直到队列为空。
752.打开转盘锁
完全平方数
对问题建模:将整个问题变成一个图论问题。
从n到0,每个数字代表一个节点;
如果两个数x到y相差一个完全平方数,则连接一条边;
就得到了一个无权图;
原来的问题就转化为,在这个无权图中找出从n到0的最短路径,所以需要BFS来完成
栈
后入先出的数据结构
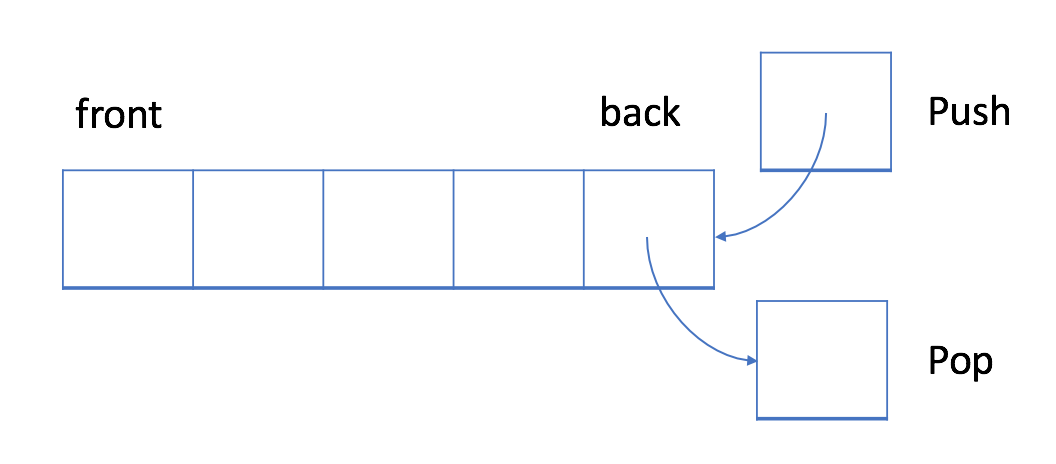
在LIFO数据结构中,将首先处理添加到队列中的最新元素。
与队列不同,栈是一个LIFO数据结构。通常,插入操作在栈中被称作入栈push。与队列类似,总是在堆栈的末尾添加一个新元素。但是,删除操作,退栈pop,将始终删除队列中相对于它的最后一个元素。
实现-栈
1 | class MyStack { |
最小栈
两个栈,一个数据栈,一个辅助栈
有效的括号
在表示问题的递归结构时,栈数据结构可以派上用场。我们无法真正地从内到外处理这个问题,因为我们对整体结构一无所知。但是,栈可以帮助我们递归地处理这种情况,即从外部到内部。
- 初始化栈
- 一次处理表达式的每个括号
- 如果遇到开括号,我们只需将其推到栈即可。这意味着我们将稍后处理它。
- 如果遇到一个闭括号,那么我们检查栈顶元素。如果栈顶元素是一个
相同类型的左括号,那么我们将它从栈中弹出并继续处理。否则,这意味着表达式无效。 - 如果到最后我们剩下的栈中仍然有元素,那么这意味着表达式无效。
每日温度
逆序遍历,为什么要使用逆序遍历。因为正常遍历思路,遍历到当前天,你无法知道后面几天的温度情况。
逆序遍历,后面几天的温度情况已经知晓,很容易得到经过几天后的温度比今天温度高。
1 | class Solution { |
1 | T = [73,74,75,71,69,72,76,73] |